Cómo hacer un producto
Uno de los conceptos más importante que trajo el movimiento Open Source es que el software1, más que un producto es un proceso. Las nuevas tendencias en gestión de proyectos retoman ese concepto. Sí, aun cuando hablen paradójicamente que lo importante es el producto. En el antiguo concepto de tipo catedral, un producto solo podía estar terminado tras meses, años o décadas. En este momento no voy a ahondar esa idea en particular. Pero quiero aportar el siguiente diagrama para tanto para el arranque como para la consecusión de proyectos. Puede ser una aplicación, una documentación, una implementación, creo que es bastante abarcativa la idea. Describiré bremvemente cada fase del diagrama:
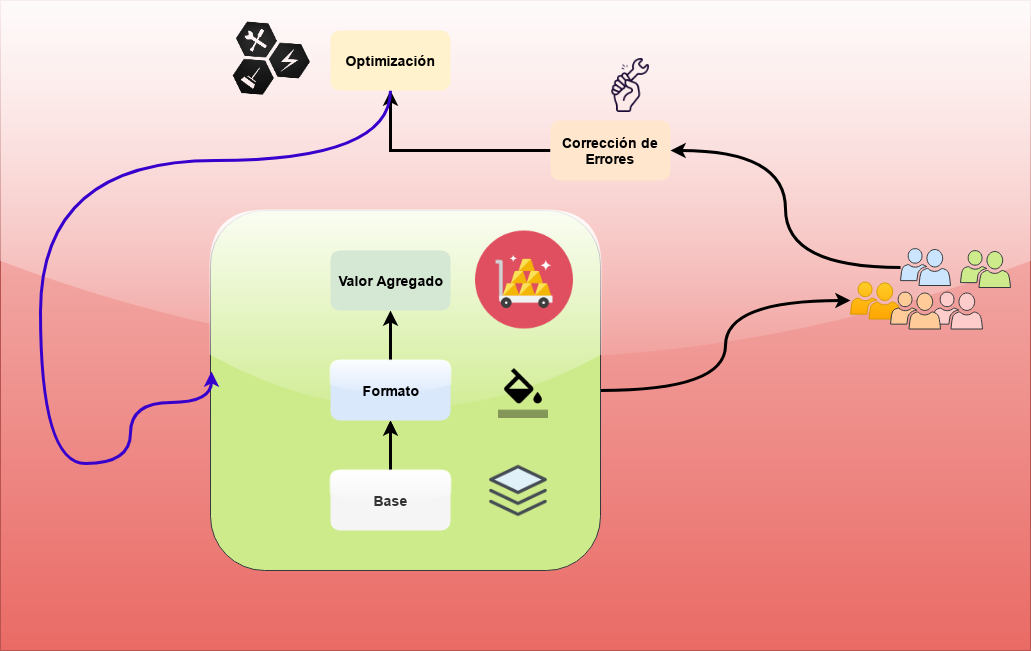
| Fase | Descripción |
|---|---|
| Base | Tiene la terminología, conceptos, herramientas fundamentales para que tenga sentido el trabajo |
| Formato | Tiene que tener una coherencia y una legibilidad o usabilidad básica para que pueda ser aprovechada por otros |
| Valor Agregado | Aquí es cuando le agregamos al trabajo ese talento especial que todos tenemos que hace distinto el producto. Al terminar esta fase el producto se considera entregable. Sea para ser presentado ante un jefe o vendido a un cliente |
| Corrección de Errores | Una vez que hemos obtenido feedback del resto del mundo, podemos corregir errores |
| Optimización | En este punto volvemos a los pasos Base, Formato, y Valor Agregado. ¿Hasta cuándo? ¿Hasta que sea perfecto? Bueno, eso no existe. La idea es iterar todas las veces que el sentido y la alegría estén presentes |
Conclusión
Si bien hay un momento en que el proceso da y debe dar como resultado un producto, es bueno tener definidas algunas fases. Una nota especial a los que padecen perfeccionismo. Es importante notar que hay dos frentes aquí. El primero es que justamente aquellos que están detrás de los resultados rápidos y atajos son muchas veces los que más hablan sobre lo perfecto que tienen que estar las cosas. El segundo frente es interno. El que siempre encuentra un obstáculo para pasar de la fase del Valor Agregado. Si bien el primer frente es incontrolable y no depende de nosotros ya que no es nuestro problema, el segundo es el que nos tiene que interesar, acallar esa vocecita que nunca quiere que obtengamos el producto. Justamente esa fase se llama Valor Agregado porque es lo que convierte tu trabajo en un producto en algo distinto. Es esa pieza que falta para que el mecanismo funcione correctamente.

Este obra está bajo una licencia de Creative Commons Reconocimiento-CompartirIgual 4.0 Internacional.