Una máquina de 64 bits no es inmune al 2038
Las computadoras no guardan la fecha como la escribimos nosotros: guardan un número, y cada familia de sistemas eligió desde cuándo contarlo. En los sistemas Unix —Linux entre ellos— ese número es la cantidad de segundos transcurridos desde el 1 de enero de 1970. Ocupa un lugar de tamaño fijo, y cuando el lugar es chico, se llena. El lugar que se usó durante décadas se llena el 19 de enero de 2038. La mayoría de las máquinas de hoy ya no tienen ese límite; algunos archivos que esas mismas máquinas siguen escribiendo, sí.
Lo que sigue está medido, no citado: cada cifra sale de correr el programa en la máquina que se nombra —una Fedora 44 y las tres versiones de RHEL vigentes—. Una de esas mediciones muestra algo que la documentación no dice: en la familia RHEL, el número de versión de glibc no alcanza para saber en qué situación está un sistema, y aplicarlo como criterio da la respuesta equivocada en la versión más nueva.
Para lo principal —saber si tus máquinas están afectadas y por qué el número de versión no te lo contesta— alcanza con moverse en una terminal y leer la salida de un comando; eso está en Dónde está parada tu máquina y en el cierre. Los tramos con código en C y aritmética de enteros explican el mecanismo: dan el fundamento, no la conclusión, y quien no los recorra llega igual al final.
Ese número se guarda en un tipo de dato llamado time_t, y de cuántos bits tenga depende hasta qué fecha puede seguir contando. Un time_t de 32 bits con signo llega hasta enero de 2038 y ahí se le termina la cuenta. Ese es el problema del año 2038.
Que una máquina sea "de 64 bits" es una etiqueta que se repite bastante más de lo que se explica. Lo que mide 64 bits son los registros del procesador —los casilleros internos donde hace sus cuentas— y las direcciones con las que ubica cada byte de la memoria: es el tamaño del número que puede manejar de un saque. En Linux sobre esas máquinas, los tipos de dato que representan direcciones, tamaños y tiempos pasaron a medir 64 bits, y time_t es uno de ellos.
Por eso en un servidor x86-64 —cualquiera con procesador Intel o AMD de las últimas dos décadas— time_t mide 8 bytes, o sea 64 bits, y con ese ancho la cuenta no se agota en ningún plazo que nos importe. De ahí se deduce que la máquina está a salvo.
Pero ese ancho es una propiedad del procesador y de los programas que se compilan para él. Un archivo que ya está escrito no participa de eso. La deducción vale para lo que el sistema calcula mientras corre, y no vale para lo que queda guardado en disco. Un archivo no guarda un time_t: guarda una cantidad fija de bytes, en un orden fijo, que se decidió cuando se diseñó ese formato. Compilar el sistema para 64 bits no cambia esa decisión, porque agrandar un campo volvería ilegible todo lo que ya está escrito. Y /var/log/lastlog, donde queda registrado el último inicio de sesión de cada usuario, es uno de esos formatos.
Si compilás esto en cualquier Fedora o RHEL:
#include <lastlog.h> #include <stdio.h> int main(void) { struct lastlog ll; ll.ll_time = -1; printf("registro: %zu bytes | ll_time: %zu bytes, %s\n", sizeof ll, sizeof ll.ll_time, (ll.ll_time < 0) ? "con signo" : "sin signo"); return 0; }
No abre /var/log/lastlog ni necesita privilegios: lo único que hace es preguntarle al compilador qué forma tiene la estructura en esa máquina. sizeof se resuelve al compilar, así que las dos primeras cifras son el tamaño del registro y el del campo de la hora. La tercera sale de una prueba sencilla: se le asigna -1 al campo y se pregunta si quedó negativo. Si el campo tiene signo, -1 sigue valiendo -1; si no lo tiene, ese mismo patrón de bits se lee como 4.294.967.295 y la comparación da falso.
En una Fedora 44 con glibc 2.43 imprime:
registro: 292 bytes | ll_time: 4 bytes, sin signo
Tres datos en una sola línea. El registro mide 292 bytes: es el tamaño fijo del casillero que le corresponde a cada usuario dentro del archivo. De esos 292, solamente cuatro guardan la fecha del último acceso — cuatro bytes, en una máquina donde el sistema cuenta el tiempo con ocho. Y esos cuatro se están leyendo como un número que no admite valores negativos, que es el detalle que decide si la cuenta se agota en 2038 o llega hasta 2106.
Por qué el campo quedó en 32 bits
struct lastlog la define glibc, no shadow —el paquete de las herramientas de cuentas de usuario, useradd, chage, passwd, y del que en RHEL sale también el comando lastlog—. glibc es la biblioteca estándar de C del sistema: además de proveer las funciones con las que los programas le hablan al kernel, define las estructuras de datos que esos programas comparten entre sí. Por eso puede fijar el formato de un archivo que ella misma no escribe.
Su declaración actual tiene una condición:
#if __WORDSIZE_TIME64_COMPAT32 __uint32_t ll_time; #else __time_t ll_time; #endif
__WORDSIZE_TIME64_COMPAT32 vale 1 en x86-64 y 0 en aarch64. Lo que expresa esa macro es que en x86-64 conviven programas de 64 bits con programas compilados para 32, y que unos y otros leen los mismos archivos del sistema. Si struct lastlog tuviera un ll_time de 8 bytes al compilarse a 64 bits y de 4 al compilarse a 32, cada uno vería una grilla distinta sobre el mismo /var/log/lastlog: donde el programa de 64 bits guardó la fecha, el de 32 leería la mitad de esa fecha, y a continuación tomaría la otra mitad como si fuera el principio del nombre de la terminal. glibc evita esa contradicción fijando el campo en 32 bits para las arquitecturas que arrastran esa compatibilidad, aunque el time_t de la plataforma sea de 64.
Es una decisión sobre el formato en disco, no sobre la aritmética del sistema. Por eso ser de 64 bits no alcanza. En aarch64, que nunca tuvo esa restricción, el mismo campo mide 8 bytes y el registro mide 296 en vez de 292 — con las consecuencias de portabilidad que ya vimos en las particularidades de lastlog.
El problema, tal como era
Hasta hace poco ese campo de 4 bytes era con signo, y de ahí sale la fecha famosa.
Con 32 bits se pueden anotar 4.294.967.296 valores distintos. Poder representar números negativos cuesta la mitad de ese total: se va en las fechas anteriores a 1970, y el valor positivo más grande que entra pasa a ser 2.147.483.647. Ese número no es una abstracción, son segundos, y 2.147.483.647 segundos son unos 68 años. Contados desde el 1 de enero de 1970, la cuenta llega hasta:
2038-01-19T03:14:07+00:00
Un segundo después desborda al valor negativo más chico. Y la ruta de lectura de shadow hace exactamente esto:
time_t ll_time; ... ll_time = ll.ll_time;
Cuando ese valor de 32 bits pasa a una variable de 64, el compilador se ocupa de que siga significando lo mismo: si era negativo, rellena los bits nuevos de manera que siga siendo el mismo número negativo. Se llama extensión de signo, y acá tiene una consecuencia visible. El registro de un login ocurrido en 2038 no se mostraría como una fecha rara del futuro: se mostraría como
1901-12-13T20:45:52+00:00
La escritura tiene la falla simétrica, y llega por dos caminos. En el propio comando, cuando lastlog -S fija una entrada a mano, es una sola línea: ll.ll_time = NOW;, donde NOW es time((time_t *) 0). En cada inicio de sesión el que escribe es el módulo pam_lastlog, que hace lo mismo en dos pasos: time(&ll_time) sobre un time_t de 64 bits y last_login.ll_time = ll_time; sobre el campo de 32. En ambos casos el valor se trunca al guardarse.
Ese es el problema del 2038 en su forma concreta: no una abstracción sobre "sistemas viejos", sino un campo de un registro de 292 bytes que un RHEL 8 o un RHEL 9 escriben hoy en cada inicio de sesión.
Lo que hizo glibc
En la versión 2.40, publicada el 22 de julio de 2024, glibc cambió el tipo de ese campo. De las notas de la versión:
Architectures which use a 32-bit seconds-since-epoch field in struct lastlog, struct utmp, struct utmpx (such as i386, powerpc64le, rv32, rv64, x86-64) switched from a signed to an unsigned type for that field. This allows these fields to store timestamps beyond the year 2038, until the year 2106. Please note that applications are still expected to migrate off the interfaces declared in
<utmp.h>and<utmpx.h>(except for login_tty) due to locking and session management problems.
Los mismos cuatro bytes, si ya no tienen que reservar la mitad de su capacidad para las fechas anteriores a 1970, llegan al doble: 4.294.967.295 segundos, otros 68 años. La cuenta se agota recién el:
2106-02-07T06:28:15+00:00
Y la extensión ahora es de ceros, no de signo: ll_time = ll.ll_time; sobre un __uint32_t produce un time_t positivo. El login de 2038 se lee como 2038.

Es la razón por la que el programa del principio imprime sin signo. Donde el campo siga declarado como int32_t imprimirá con signo, y eso —y no el número de versión de glibc, por los motivos que veremos al final— es lo que hay que medir antes de afirmar en qué situación está una máquina concreta.
Lo que ese cambio gana, y lo que no
El cambio se lee de dos maneras equivocadas: "el problema está resuelto" o "fue un parche inútil". No es ninguna de las dos.
Gana 68 años sin tocar el formato. El registro sigue midiendo 292 bytes, los offsets siguen siendo UID × 292, y un archivo escrito antes del cambio se sigue leyendo igual. De los 32 bits, hay uno —el de más peso— que en la lectura con signo es el que indica si el número es negativo. Todas las marcas anteriores a 2038 lo tienen en cero, así que esos mismos bytes significan lo mismo con o sin signo. Precisamente por eso el cambio era viable: no rompe nada de lo que ya está escrito.
No ensancha nada. El campo sigue teniendo 32 bits. La pared se corrió, no desapareció.
No es una maniobra exclusiva de glibc. MariaDB llegó a la misma pared y salió por la misma puerta: desde su versión 11.5, el tipo TIMESTAMP pasó de 2038 a 2106 reinterpretando como sin signo el mismo campo de cuatro bytes, sin tocar el formato en disco —"storage of timestamp is not affected by the change", dice el reporte— y solo en plataformas de 64 bits. Dos proyectos sin relación entre sí, con la misma restricción y la misma salida, hasta la misma fecha.
Cambia el significado de un valor sin que el archivo lo declare. Un registro con ese bit en uno significaba 1901 antes del cambio y significa 2038 o más después. En la práctica es inocuo, porque nadie tiene logins anteriores a 1970. Pero el archivo no tiene número de versión ni campo de tipo: nada adentro dice bajo qué interpretación fue escrito. Lo que decide es la glibc del binario que lo lee.
Por qué no bastaba con agrandar el campo
Si el campo pasara de 4 a 8 bytes, sizeof(struct lastlog) pasaría de 292 a 296. Pero el archivo no guarda el nombre del usuario: la identidad de cada registro es su posición, calculada como UID × sizeof(struct lastlog). Cambiar el tamaño del registro cambia todos los offsets a la vez. El archivo entero deja de ser legible, y no hay ningún campo adentro que permita detectar con qué tamaño fue escrito.
Un formato que indexa por posición no puede evolucionar su registro. Esa rigidez es el precio de poder saltar directo al registro de un usuario sin recorrer el archivo, y es lo que convierte al ensanchamiento del campo en un callejón sin salida. Pasar a unsigned fue la única maniobra posible sin romper compatibilidad, y funciona porque no cambia ni un byte del formato.
El arreglo de verdad: lastlog2
lastlog2 es un proyecto de Thorsten Kukuk integrado en util-linux 2.40. Abandona el archivo indexado por posición y guarda los datos en una base SQLite3 en /var/lib/lastlog/lastlog2.db, con una tabla cuya clave es el nombre de usuario:
CREATE TABLE Lastlog2( Name TEXT PRIMARY KEY, Time INTEGER, TTY TEXT, RemoteHost TEXT, Service TEXT );
Escribir un login es un REPLACE INTO por nombre; leer es un SELECT por nombre. La marca de tiempo es un entero de 64 bits, y el tamaño de la base depende de la cantidad de usuarios con registro, no del UID más alto. Los datos los recolecta un módulo PAM, pam_lastlog2, que reemplaza a pam_lastlog.
Cada diferencia cierra uno de los problemas de la trilogía: la clave por nombre elimina las colisiones de UID; la base densa elimina el archivo disperso y su tamaño aparente descomunal; el entero de 64 bits elimina la fecha límite. Y como la identidad ya no es la posición, el esquema puede crecer: el campo Service no existía en struct lastlog y no podría haberse agregado.
Una aclaración cronológica: la justificación que da el propio proyecto —"the standard /var/log/lastlog implementation using lastlog.h from glibc uses a 32bit time_t"— se escribió cuando el campo todavía era con signo. El cambio de glibc corrió la fecha, no eliminó el motivo.
Fedora migró a lastlog2 como default del sistema en su versión 43. En una Fedora 44 el binario lastlog ya no existe, /var/log/lastlog queda como un archivo vacío, y rpm -ql shadow-utils | grep -i lastlog no devuelve nada. glibc, en cambio, sigue instalando <lastlog.h>: la estructura sobrevive al programa.
utmp y wtmp corren la misma suerte
El cambio de glibc 2.40 alcanzó también a struct utmp y struct utmpx, que sostienen /run/utmp, /var/log/wtmp y /var/log/btmp. Se verifica con el mismo programa, cambiando <lastlog.h> por <utmp.h>, la estructura por struct utmp y el campo por ut_tv.tv_sec:
sizeof(struct utmp) = 384 | ut_tv.tv_sec = 4 bytes, sin signo
La diferencia es que ahí no hay un lastlog2 esperando. La dirección de upstream, sostenida por el mismo autor, es dejar de escribir utmp y consultar a systemd-logind a través de las funciones sd_*() de libsystemd. Es un reemplazo más ambicioso que cambiar un backend de almacenamiento, y por eso avanza más despacio.
Dónde está parada tu máquina
Tres comprobaciones, ninguna destructiva.
La primera es el programa del principio, que lee la estructura tal como la ve el compilador de esa máquina. Si no hay compilador a mano, la declaración se puede mirar directamente en el archivo donde glibc la define, que viene en el paquete glibc-devel:
grep -A6 'struct lastlog' /usr/include/bits/utmp.h
La primera rama es la que se compila en x86-64 y en las demás arquitecturas que arrastran compatibilidad con programas de 32 bits: int32_t significa 2038, __uint32_t significa 2106. La segunda rama, __time_t, es la de aarch64, donde el campo mide 8 bytes y el problema no existe.
La segunda:
ls -l /var/lib/lastlog/lastlog2.db
Si existe, el sistema ya está en el esquema SQLite y el problema no aplica.
La tercera:
ls -ls /var/log/lastlog
Si informa un tamaño aparente grande y una ocupación mínima, el archivo indexado por UID sigue vivo, y con él tanto la fecha límite de su campo de 32 bits como todo lo que ya sabemos sobre no rotarlo y no meterlo en un backup a nivel de archivo.
Lo que conviene no hacer es deducirlo del número de versión. rpm -q glibc parece suficiente, porque el cambio es de 2.40, pero las distribuciones retroportan. En la familia de RHEL el número de versión no alcanza para deducir la respuesta:
| Sistema | glibc | Campo | Límite |
|---|---|---|---|
| RHEL 8.10 | 2.28 | int32_t |
2038 |
| RHEL 9.8 | 2.34 | int32_t |
2038 |
| RHEL 10.2 | 2.39 | __uint32_t |
2106 |
RHEL 10 tiene el arreglo sin haber llegado a 2.40: Red Hat lo retroportó a su glibc 2.39 en mayo de 2024, en la entrada 2.39-12 del changelog del paquete. Quien aplique el criterio de la versión sobre RHEL 10 va a concluir que está expuesto a 2038, y no lo está. Las tres filas salen de correr el programa dentro de ubi8, ubi9 y ubi10, que llevan la glibc de cada RHEL.
Lo mismo en una máquina de 32 bits
Nada de esto es propio de RHEL. En una Debian 12 sobre i386 el mismo grep devuelve int32_t. Y ahí el campo de cuatro bytes no está solo: en una máquina de 32 bits todos los programas guardan el tiempo en cuatro bytes, no únicamente los que tocan lastlog. Con el reloj puesto más allá de 2038, esa máquina ni siquiera termina de arrancar: el programa que le entrega el control al sistema definitivo pide los datos de un directorio, la fecha no entra en el campo, y el arranque se queda en el shell de emergencia.
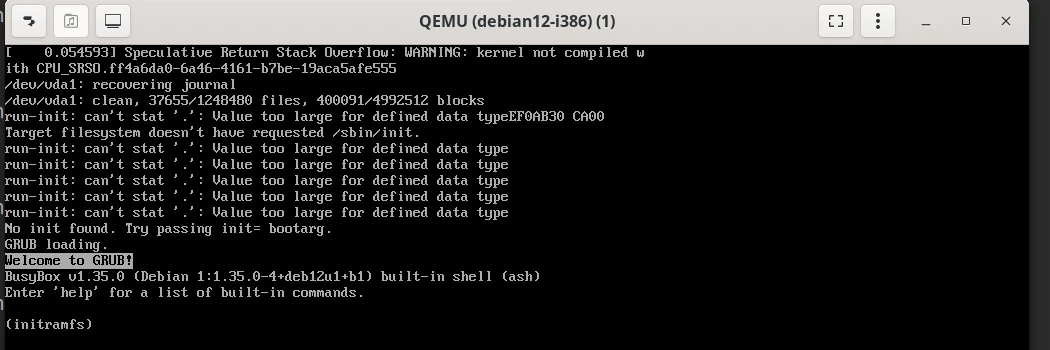
El disco está sano y el kernel también: el propio arranque informa que el sistema de archivos está limpio, con sus 37.655 archivos en su lugar. Lo único que pasó es que una fecha dejó de entrar en un campo de cuatro bytes.
Y esa máquina va a seguir así: cuando Debian pasó sus arquitecturas de 32 bits a tiempos de 64 bits, en la versión 13, dejó a i386 deliberadamente afuera. La razón es que i386 se mantiene para correr binarios viejos, y cambiar el tamaño de los tipos rompería justamente esa compatibilidad. De todos modos, la diferencia con lastlog se sostiene: este es un problema que se arregla recompilando los programas —Debian lo hizo para el resto de sus arquitecturas de 32 bits— y el de lastlog no, porque recompilar no cambia lo que ya está escrito en disco.
ls -l /var/lib/lastlog/lastlog2.db
Si existe, el sistema ya está en el esquema SQLite y el problema no aplica.
ls -ls /var/log/lastlog
Si informa un tamaño aparente grande y una ocupación mínima, el archivo indexado por UID sigue vivo, y con él tanto la fecha límite de su campo de 32 bits como todo lo que ya sabemos sobre no rotarlo y no meterlo en un backup a nivel de archivo.
Para qué se corrió la pared
Los 68 años que agregó el cambio no son para llegar a 2106. Nadie va a estar leyendo /var/log/lastlog en 2106: el reemplazo ya existe, ya es el default en Fedora, y no hay un tercer truco disponible. Cuatro bytes sin signo llegan a 4.294.967.295 y ahí se termina — no queda nada que reinterpretar. Correr la época (epoch), empezar a contar desde 2038 en vez de desde 1970, tampoco sirve: a diferencia del cambio de signo, haría que cada valor ya escrito significara otra cosa, y el archivo no tiene adentro ningún campo que diga bajo qué época fue guardado.
Los 68 años son para las máquinas que ya están andando. Una RHEL 8 instalada este año va a seguir en producción bien entrados los 2030, con su campo con signo y su fecha límite en 2038 — que está a doce años, no a ochenta. RHEL 9 está en la misma situación. Para esas máquinas el problema no es lejano: es la vida útil del servidor que alguien está montando ahora.
Eso es lo que hace el cambio de glibc. No arregla el formato, que sigue sin poder crecer. Le da al reemplazo el tiempo de propagarse al ritmo al que se reemplazan los servidores, en lugar del ritmo de una urgencia.
Fuentes y más recursos
-
glibc 2.40 — anuncio de la versión — el párrafo que documenta el cambio de
signedaunsigneden el campo de época destruct lastlog,utmpyutmpx, y el corrimiento del límite a 2106. -
Y2038, glibc and utmp/utmpx on 64bit architectures — Thorsten Kukuk explica por qué una máquina de 64 bits no es inmune: el
time_tde 32 bits que sobrevive en los formatos de utmp y lastlog. -
glibc.spec de CentOS Stream 10 — el changelog del paquete, donde consta el retroporte del cambio a la glibc 2.39 de RHEL 10: "Use unsigned types in
<utmp.h>/<utmpx.h>". - MDEV-32188 — make TIMESTAMP use whole 32-bit unsigned range — el mismo movimiento en MariaDB: de 32 bits con signo a 32 bits sin signo, de 2038 a 2106, sin cambiar el formato de almacenamiento. Corregido en 11.5.1.
-
Proyecto lastlog2 — el reemplazo Y2038-safe con backend SQLite3:
liblastlog2, la CLI ypam_lastlog2. -
util-linux 2.40 — Release Notes — la integración de
lastlog2ypam_lastlog2en util-linux. -
Fedora Change: Migrate to lastlog2 — la adopción de
lastlog2como default del sistema, desde Fedora 43.
La serie
| Parte | Post | De qué trata |
|---|---|---|
| 1 | Archivos sparse en Linux | Los agujeros: cómo un archivo declara un tamaño y ocupa otro |
| 2 | Particularidades de lastlog | El UID como posición dentro del archivo, y todo lo que se desprende de esa decisión |
| 3 | Una máquina de 64 bits no es inmune al 2038 (estás acá) | El campo de fecha de 32 bits, lo que hizo glibc y el reemplazo |