La mitología en torno a la memoria en Linux ha producido una serie de relatos:
- En un extremo: Linux puede funcionar con muy poca memoria RAM.
- Del otro lado: Linux consume mucha memoria.
- Y que una partición swap debe tener entre 1 a 2 veces la memoria RAM.
Como vemos, algunas historias son más recientes, otras más antiguas, pueden ser parcialmente ciertas y hasta contradictorias entre sí.
Este artículo tiene como propósitos:
- Explicar de manera sencilla el funcionamiento de la memoria en Linux, desmitificando también algunos conceptos.
- Enumerar y describir tácticas para que el uso de la memoria proporcione la mejor usabilidad y experiencia del usuario.
- Ofrecer alternativas para que cada uno elija la mejor opción de acuerdo a sus necesidades.
Definiciones
Vamos a repasar algunos conceptos básicos que de manera más o menos frecuente usamos, usaremos metáforas en el camino. Ninguna metáfora es perfecta, sin embargo ellas nos ayudan a entender la realidad.
Memoria Virtual
La memoria virtual es el mecanismo por el cual cada proceso recibe un espacio de direcciones propio, independiente y protegido. El hardware traduce direcciones virtuales a físicas según tablas de páginas. Esto permite aislamiento, sobreasignación, mapeos de archivos y demanda dinámica de páginas, más allá de la cantidad de RAM disponible.
Linux trata de usar la mayor cantidad de memoria posible, para poder ejecutar las aplicaciones y acceder a los archivos de la manera más rápida posible. De manera que si la memoria libre es baja no es necesariamente un indicativo de un problema.
Page
Una página es la unidad mínima de memoria, de tamaño fijo (típicamente 4 KB), que el kernel y el hardware de gestión de memoria del procesador utilizan para organizar el espacio de direcciones y realizar el mapeo entre direcciones virtuales y físicas.
Page table
Es una estructura de datos jerárquica administrada por el kernel y usada por el hardware para traducir direcciones virtuales a direcciones físicas, con información de permisos y estado de cada página.
Page Fault
Un page fault ocurre cuando un proceso accede a una dirección válida de su espacio de memoria pero la página correspondiente no está preparada para ese acceso. Puede deberse a que la página aún no fue cargada, a que debe asignarse, o a que debe traerse desde disco. Si la página no está en RAM, el kernel debe cargarla, lo que puede ser lento; si ya estaba en RAM, el costo es menor.
Page cache
Es la caché de páginas de archivos gestionada por el kernel, usada para acelerar lecturas y escrituras almacenando en RAM los datos y metadatos de archivos y directorios, reduciendo accesos al disco.

Tipos de memoria
File Memory
Es la memoria relacionada con el Page Cache.
Anonymous Memory
Es la memoria que un proceso usa y que no está respaldada por un archivo: heap (asignada dinámicamente), stack (llamadas a funciones y almacenamiento de variables locales), COW (parte de la memoria cuando se crea un proceso hijo) y mapeos con MAP_ANONYMOUS. Su único respaldo posible es la swap.
La memoria anónima se crea y utiliza en RAM. Si el kernel necesita expulsarla de RAM, su único destino posible es la swap, porque no tiene un archivo desde el cual reconstruirse. Pero su existencia normal no depende de la swap.
Memory Pressure
Memory pressure es un estado en el que las páginas libres caen por debajo de umbrales críticos, obligando al kernel a iniciar mecanismos de liberación de memoria.
En términos prácticos cuando la presión es alta pueden surgir ciertos síntomas:
-
Sitios web / servidores HTTP:
La latencia aumenta porque los workers deben esperar a que el kernel libere páginas. Además, puede haber más CPU gastada en recuperar memoria, lo que degrada aún más los tiempos de respuesta.
-
Sistemas de escritorio:
El sistema pierde fluidez porque el scheduler empieza a verse afectado por stalls debidos a las operaciones para liberar memoria y, si hay swap, el sistema puede entrar en swap thrashing. Esto produce lag del mouse, ventanas que tardan en responder, escritorios congelados por segundos, etc.
-
Acceso remoto (SSH, RDP, VNC):
Al haber presión, las operaciones de usuario-espacio tardan más en ejecutarse, y los daemons pueden quedar brevemente estancados esperando memoria. Esto causa retrasos notables en la interacción remota.
¿Y qué sucede si la presión de memoria puede llegar a ser tan alta que el kernel ya no logra conseguir memoria ni siquiera después de intentar liberarla?
Thrashing
El thrashing ocurre cuando la memoria RAM no alcanza para mantener las páginas que los procesos usan todo el tiempo. El kernel empieza a sacar páginas de memoria para hacer lugar a otras nuevas, pero enseguida vuelve a necesitarlas. Esto genera un bucle de fallos de página y de recarga constante desde el disco.
-
Con swap: las páginas anónimas van y vienen entre RAM y swap, lo que dispara el uso de disco y vuelve el sistema extremadamente lento.
-
Sin swap: las páginas anónimas no tienen adónde ir y el kernel termina activando el OOM killer.
-
Incluso sin swap: puede haber thrashing si las páginas vienen de archivos (page cache), ya que el kernel debe recargarlas una y otra vez.
OOM (Out-Of-Memory) 💀 🔥
Out-Of-Memory es una situación en la cual el kernel agotó todos los mecanismos para liberar memoria:
- Liberar páginas del caché.
- Mover páginas anónimas a la swap.
- Compactar memoria.
- Liberar memoria mediante
kswapd.
- Aplicación de políticas de cgroups (muy común al usar contenedores).
OOM killer
El OOM killer es el mecanismo que usa el kernel cuando ya no puede asignar más memoria, incluso después de intentar liberar todas las páginas que es posible descartar o mover fuera de la RAM.
En esa situación crítica, el kernel calcula un puntaje para cada proceso (oom_score) y finaliza al que resulte más conveniente para recuperar memoria rápidamente y permitir que el sistema siga funcionando.
Este comportamiento puede influenciarse ajustando oom_score_adj, que hace que un proceso sea más o menos propenso a ser elegido.
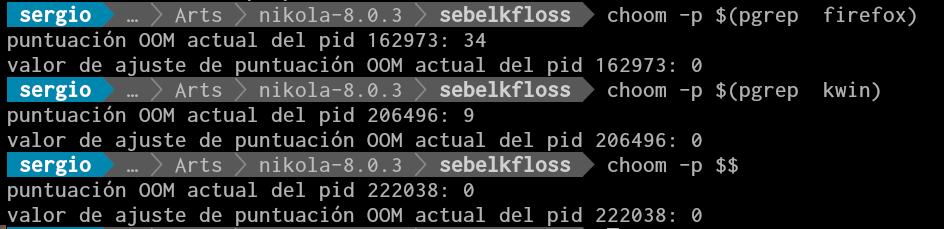
oom_score
Como ya se mencionó a cada proceso se le asigna un puntaje de acuerdo a distintos factores, cuanto más alto es, más susceptible es a ser terminado por OOM killer.

Y también, como dijimos mediante oom_score_adj podemos influir en el score de un proceso:

En versiones más recientes de las distribuciones existe el comando choom que permite ver y/o ajustar dicho valor.
Swap
Los usuarios ocasionales de Linux y aun muchos sysadmins tienen una idea negativa sobre "la swap". Simplificaciones extremas y conceptos anticuados la han convertido en la gran villana de la historia del sistema operativo.
Si comparamos a la memoria con un escritorio, sin swap podría lucir así:

Photo by Ashim D’Silva on Unsplash
Así que primero vamos a decir lo que no es:
-
No es la memoria virtual sino que forma parte de la técnica que realiza el sistema operativo para administrar la memoria.
-
No es un espacio de reserva ni un último recurso. Es un espacio complementario que sirve para liberar RAM.
-
No funciona como último recurso, pero el sistema operativo puede mover hacia la swap las páginas de memoria no usadas recientemente.
-
No es algo de lo que el sistema operativo pueda prescindir alegremente, aun cuando la cantidad de memoria RAM física sea grande. Quienes parecen haber inventado la pólvora, nos cuentan que es posible técnicamente que Linux funcione sin swap. Si bien es cierto, al carecer de swap, el kernel no tiene manera de mover páginas de memoria anónimas hacia el área de swap y liberar así RAM para procesos que la necesitan urgentemente.
Nuestro escritorio con swap:

Photo by Alexandru Acea (edited by me) on Unsplash
¿Los cajones de un escritorio los usamos cuando lo tenemos abarrotado de cosas? No, los usamos para guardar cosas que no son de alta prioridad. Aunque es cierto, si luego queremos usar esa tijera o aquel destornillador en algún momento requerirá un poco más de trabajo, tendremos que abrir el cajón, buscarlo, extraerlo, etc.
Ah, y la swap también sirve para hibernar, aunque honestamente no sé cuánta gente mantiene esa práctica.
Tuning
Ahora veremos diferentes tácticas que podemos usar para optimizar el uso de la memoria.
cgroupv2
cgroup es un mecanismo para organizar los procesos de manera jerárquica y distribuir los recursos del sistema a lo largo de la jerarquía en una manera controlada y configurada.
Un cgroup se compone de un núcleo que es responsable primariamente de organizar de manera jerárquica los procesos y controladores que comúnmente distribuyen un tipo específico de recurso del sistema a lo largo de la jerarquía.
En la versión 2 de cgroup un proceso no puede pertenecer a diferentes grupos para diferentes controladores. Si el proceso se une al grupo alfa, todos los controladores para alfa tomarán control de ese proceso.

Supongamos que queremos que los procesos de un cgroup (y sus grupos hijos) conserven su memoria y no sean los primeros en perderla cuando el sistema necesita liberar RAM. Para eso sirve el parámetro memory.low: mientras el uso de memoria del cgroup se mantenga por debajo de ese valor, el kernel evita quitarle páginas y prefiere reclamarlas de los otros cgroups que no están protegidos. Recién cuando ya no queda nada por reclamar en otro lado toca la memoria protegida.

Otro parámetro interesante para monitorear es memory.pressure. Tiene dos líneas, some y full, que registran cuánto tiempo hubo tareas demoradas por falta de memoria. Entonces si miramos el archivo /sys/fs/cgroup/user.slice/memory.pressure:
some avg10=0.00 avg60=0.13 avg300=0.12 total=1690238
full avg10=0.00 avg60=0.10 avg300=0.09 total=1394199
Significa que, dentro del grupo de control user.slice, en los últimos 10 segundos no hubo tareas afectadas por presión de memoria. Sin embargo, en el último minuto las tareas estuvieron bloqueadas un 0,13% del tiempo y un 0,12% en los últimos cinco minutos. El valor total indica que estas situaciones acumulan aproximadamente 1,7 segundos de espera.
La segunda línea muestra las mismas métricas, pero aplicadas a los casos en que todas las tareas del grupo estuvieron simultáneamente afectadas por presión de memoria (full en lugar de some).
Es decir:
zram
zram es por así decirlo, una manera cool de usar swap gracias a un módulo del kernel.

Photo by chuttersnap on Unsplash
En lugar de gastar espacio en un disco (sea rígido o sólido) usamos dispositivos de bloque en la propia RAM. Los bloques swapeados se guardan comprimidos. Estos discos virtuales son rápidos y ahorran memoria.
Una de las pocas desventajas que tiene esta metodología es la incapacidad para poder hibernar el sistema operativo, al no estar presente la partición en un almacenamiento de tipo persistente.

EarlyOOM
El OOM killer del kernel solamente se dispara en situaciones extremas y le puede llevar mucho tiempo hasta que puede enviar SIGKILL a los procesos que sean necesarios para poder liberar memoria. Durante ese tiempo probablemente el usuario no pueda interactuar con el sistema operativo.
EarlyOOM trabaja en espacio de usuario y por lo tanto se puede anticipar y ser mucho más rápido.
El comportamiento predeterminado en Fedora es que si tanto la RAM como la swap libre caen por debajo del 10%, EarlyOOM le envía una señal de terminación al proceso con el oom_score más alto. Si la RAM como swap libre bajan por debajo del 5%, EarlyOOM le enviará una señal para matar a ese proceso, el de oom_score más elevado.
La idea es recuperar la usabilidad (especialmente en un entorno de escritorio) lo antes posible.
El problema es que EarlyOOM no soporta al momento la medición de la memory pressure como indicativo para tomar decisiones.
nohang
Este servicio es mucho más configurable y aporta una mejor solución que EarlyOOM.
Algunas funcionalidades son:
- Se puede elegir la acción que realizará en una situación OOM.
- Ofrece varios criterios para elegir los procesos a finalizar.
- Soporta zram
- Puede usar memory pressure para tomar una acción.
- El archivo de configuración es medianamente sencillo
Sin embargo, este proyecto en la actualidad tiene poca actividad comparado por ejemplo con EarlyOOM

zswap
Con zswap no reemplazamos el espacio swap en el disco sino que usamos un caché comprimido en la RAM. Este método ahorra I/O, obteniendo entonces mejor rendimiento y alargando la vida útil de discos flash o sólidos. La única desventaja es usar algo de tiempo del procesador para realizar la compresión.

Photo by Pineapple Supply Co. on Unsplash
Mediante el caché se logra una diferenciación entre páginas más usadas (zswap) y menos usadas (swap).
systemd-oomd
El servicio systemd-oomd es un proyecto en el que comenzó en Facebook para integrarlo con systemd. En un principio estaba pensado para manejo de memoria a gran escala, y bastante más complejo de configurar. Sin embargo ha sido adoptado desde Fedora 34 reemplazando a EarlyOOM. En las distribuciones que usan versiones recientes de systemd, está disponible, aunque no todas lo habilitan de manera predeterminada.

Resumen
- Swap no es la villana de la película
- El tuning de cgroupv2 puede traer grandes beneficios, no obstante existen proyectos y distribuciones que no lo usan.
- EarlyOOM es una solución rápida y aplicable a una amplia gama de sistemas Linux, aunque no siempre es la más exacta ni más elegante.
- El servicio nohang (o nohang-desktop) es una opción más madura aunque algo más compleja que EarlyOOM, pero que sin embargo ha caído en cierta inactividad.
- El servicio systemd-oomd inicialmente incorporado por Facebook es seguramente la opción más adecuada para escenarios más complejos y de manejo de memoria a gran escala. También es utilizado actualmente en sistemas de escritorio.
- Sin embargo, muchas distribuciones o sabores de distribuciones prefieren usar el mecanismo clásico de OOM killer.
- A veces se sugiere el ajuste de parámetros del kernel mediante
sysctl.
- Si se desea ahorrar espacio en disco se puede reemplazar la swap por zram, sacrificando la opción de hibernar el sistema.
- La opción zswap es más sofisticada, aunque dependemos del uso de swap en disco.
Photo by sk on Unsplash
Fuentes consultadas